Adding Playwright Agents: Lessons from the Deep Trenches
I have spent the last few weeks adding AI agents to my Playwright framework. Specifically Playwright’s planner, generator, and healer, running locally through Claude Code. The Playwright agents explore the UI of our payment platform and write tests that match the framework I’ve been building for three years. This post is a brain dump on what worked, what didn’t, the token costs, and what I’m changing next. I am writing it mostly so I don’t forget. If anyone else is heading down this road, hopefully it saves you a step.
The Setup
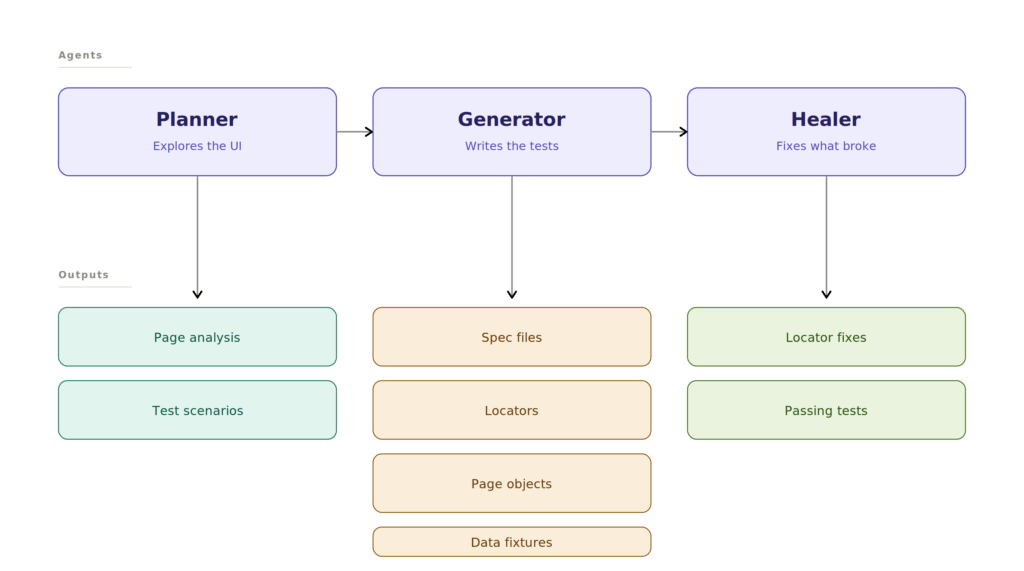
The three agents are Playwright’s own. See playwright.dev/docs/test-agents.
- The Planner. Explores the UI, documents components and locators, produces a test plan.
- The Generator. Takes the plan and writes the actual Playwright tests.
- The Healer. Runs the generated tests, identifies failures, fixes them.
Starting With MCP, And Abandoning It Fast
My first approach was MCP. Claude Code told me Playwright agents only worked through MCP and that playwright-cli did not support agents. But I watched Playwright’s own YouTube video on MCP vs CLI and the Lie Detector Determined That Was a Lie.

Playwright agents support playwright-cli directly. The video specifically called out that the CLI is built for agents and is dramatically less token hungry than MCP. The benchmark Playwright showed on screen was 114k tokens versus 27k tokens for the same task. That works out to roughly 57% versus 13.5% of Claude’s 5 hour window, which lines up with what I saw in my own runs.
If you are running agents against a Playwright framework and you have not looked at playwright-cli yet, go read this article by Anirban first. The short version. playwright-cli snapshot gives the agent a compact structured view of the live page for around 150 tokens, instead of the agent reading source files and guessing what the DOM looks like.
How I Set the Project Up
Before running anything, I had Claude learn the codebase. After it had context, I had it generate a CLAUDE.md file documenting the framework. It did a good job. Then I had it rewrite the Playwright-provided agent definitions to use CLAUDE.md as context. That single change improved both the planner and generator output a lot.
I also generated an AI.md to document the toolchain itself. How the agents are invoked, the slash commands, the file layout, the auth flow. About 5 corrections needed but otherwise solid as a reference doc for the team.
The playwright-cli --skills command was run after install as part of Playwright’s documented setup. The agents had local command docs from the start because of that.
Running the Pipeline, And What It Cost
Here is what running all three agents actually cost on basic Claude Code, not enterprise:
| Agent | Token Usage | Tokens | Notes |
|---|---|---|---|
| Planner | 78% | 156k | Burned most of the 5-hour window solo |
| Generator | 39% | 78k | Run in the next window |
| Healer | 46% | 93k | Longest wall-clock time, less tokens than expected |
| Generator + Healer combined | 85% | 170k | Near the window limit |
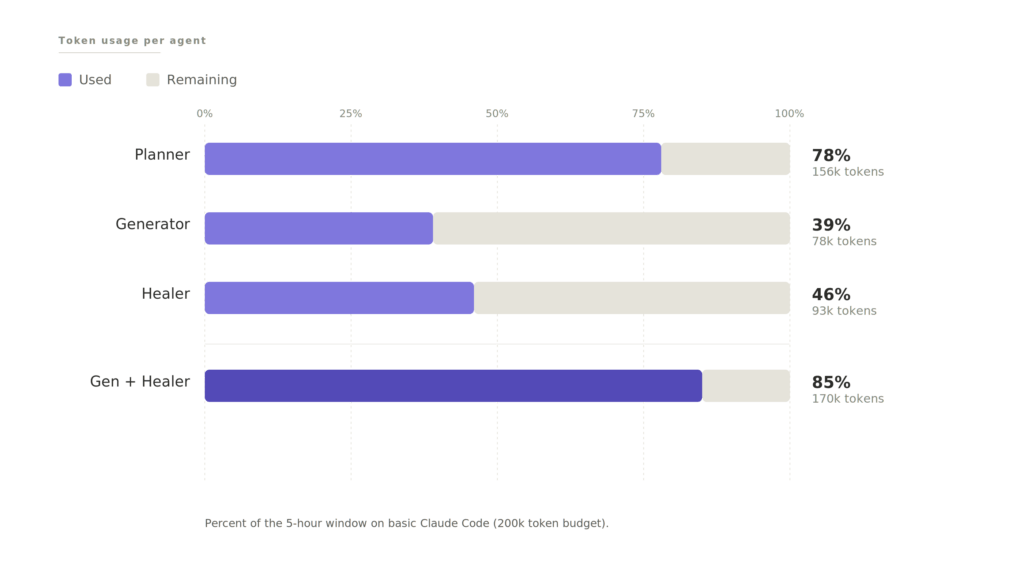
Using basic Claude Code, not the enterprise tier, I ran through 78% of my 5-hour usage on the planner alone. That meant waiting for the window to reset before running the generator and healer. What should have been one run turned into a full day.
The healer surprised me. It ran for over an hour but used less tokens than the planner. Makes sense in hindsight. The planner is doing complex analysis. Exploring the UI, documenting components, generating scenarios. The healer is doing tedious repetitive work. Run test, read failure, fix locator, repeat. Repetitive is cheaper than complex.
The Results
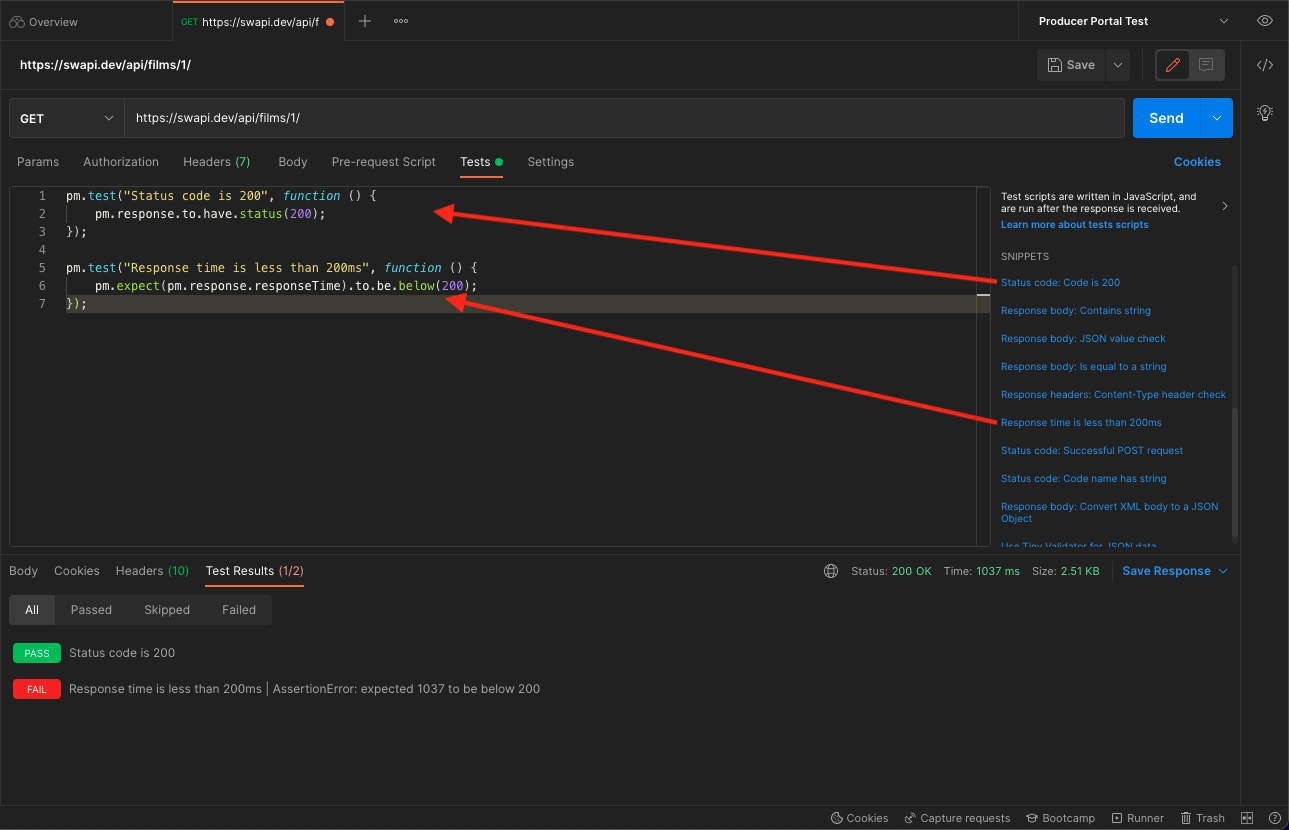
The generator produced 47 tests. 18 of them failed when I ran them. 29 passed.
Then I ran the healer.
After the healer finished, 45 tests were green. 2 of the 47 had been flagged as bugs along the way.
The 2 flagged bugs were not real. The agents flagged validation that only triggers after clicking the Apply button, not before. That is a design decision in our framework, not a defect. The agents did not have context on that. Something to address in the planner prompt going forward.
So 47 passing tests, 0 real bugs missed. Looks great on paper.
Then I reviewed the code.
Notes on the Planner
The planner is based on Playwright’s official planner. Modified to understand my codebase through CLAUDE.md. It does two things in one pass.
First, it analyzes the page. What is on the page, how the elements work, what options each element has, file references, and locators. On this run it produced a 936-line markdown file. Thorough.
Second, it generates test scenarios from that analysis.
A few problems came up.
- Some of the locators it captured were too generic and needed the healer to clean up later
- The agents needed to run through the project’s
uiSetupto ensure they were logged in. Once I told the agent aboutuiSetup, it added the handling automatically, including login refresh logic for long runs - A handful of the generator’s assumptions were understandable but wrong, which I will get to below
The bigger architectural thought. The two things the planner does do not need to happen in the same agent run. The page analysis and the test scenarios are different artifacts with different lifespans. The page analysis is reusable, since the page does not change every day, and a cached version could feed future scenario generation at a fraction of the tokens. The test scenarios are throwaway after the tests exist. However this is just a theory of mine and has yet to be verified.
Notes on the Generator
The CLAUDE.md context carried over to the generator and it understood the framework. playwright-cli --skills ships with a built-in test generation skill that helped here.
The generator wrote tests, page objects, locator files, and data fixtures following the framework’s conventions. The first impression was strong.
One real problem. The generator always creates a new spec file. It knew which files to reference when building tests, but it never checked whether a similar test already existed or whether it should insert into an existing spec. Every run produces a new file. That is going to create duplicates fast. This needs to be fixed before the agents run in any kind of automated way.
Notes on the Healer
Watching the healer work was satisfying. It runs the test, sees the failure, opens a playwright-cli session, inspects the UI, and repairs the broken locator. Then runs again. Most of what it fixed was locators from the generator that probably did match the DOM but were flaky or not unique enough.
Two things I am changing about how the healer runs.
First, scope. Right now the healer can end up running the full suite to triage one failing test. The article by Anirban covers exactly this. Use --grep to scope test runs to the specific failure, and use --reporter=json so the agent parses structured output instead of pattern-matching terminal text. Same fix, way cheaper.
Second, guardrails. I read a story recently, and I cannot find the source, where someone’s AI healer “fixed” a failing test by injecting JavaScript into the UI to make the bug disappear. Not by fixing the test. Not by flagging the bug. By hiding it. The test passed. The bug was still there.
I have not seen my healer do this. But “the AI healed the test” can mean a lot of different things and I want to be very clear about what mine is and is not allowed to do.
Notes on the Generated Code
The page I was testing auto-applies last-month date filters through the URL. The generator wrongly assumed it had to calculate the date range and append the parameters to the URL itself, instead of just navigating to the page and letting it do its thing. It did extra work to arrive at the same place, which is a very AI mistake to make.
The locators are great after the heal. That part works.
The data fixture has some useless code that needs refactoring. I am chalking that up to a product knowledge gap. As we build out more skills and markdown context, that should improve.
Some of the future-date logic in the fixtures is static when it should be dynamic. In 4 years the code would not work. Then again, why would you be running this code 4 years from now? coughs in COBOL
Then the big one.
The tests are supposed to validate filters. The generated pattern is:
- Set the filter in the UI
- The UI updates the URL to match the filter
- The test verifies the URL contains the filter
- The test verifies the table is present
That is it.
The test does not verify that the contents of the table actually match the filter. Some of the tests do not even validate what filter was set. There are no locators for the table the filter is supposed to be filtering.
Concrete example. If I set the filter to September 9, 1947*, the test only checks that the URL includes the date. It never checks that the table on the page is showing entries from that date. The test passes. The filter could be returning every record from the Cretaceous period and the test would still go green. We would have a wall of passing tests guarding nothing. That is worse than no tests at all, because at least with no tests you know what you do not have.
So Whose Fault Is This?
When I went back to the planner output, the planner never planned for the tests to check anything beyond the URL. The generator did exactly what the plan said.
So is this a planning failure or a prompt failure on my end?
It is on me. I expected the planner to be capable of more than what it was based on what I had heard from the community. The tests are lacking, and we will need to be more thorough with our prompts.
That is the lesson for anyone else heading down this road. AI agents will do exactly what you ask. They will not infer what “good test coverage” means. “Test the filters” is not a complete prompt. “Test that the filter changes the URL AND that the table updates to match the filter criteria” is closer to the bar.
What I Am Changing Next
Going forward.
Split the planner workflow. The planner creates two things, a page analysis and a set of test scenarios. Those can be split. The generator runs after the planner, against both files, and produces the locators.js file. Once the generator is done, I can go back to the page analysis and insert a reference to the locator file. The test scenarios can be deleted once the tests are generated. The page analysis sticks around for reuse on future runs against the same page.
Teach the generator about existing spec files. No more always-create-new-spec behavior. It needs to check whether a relevant spec exists and insert into it.
Implement Anirban’s --grep and --reporter=json patterns for the healer. Scope every healer run. No more full-suite triage for one failing test.
Write better prompts. Specifically for the planner. The “table contents must match the filter” problem is not solvable by the agent figuring it out. It has to be told.
The Real Bottleneck
I keep reading articles and Reddit threads making the same point and I think they are right. AI moves the bottleneck, it does not remove it. Code generation is faster. Code review is the same speed it always was. Maybe slower, because now you are reviewing code you did not write and do not have the same mental model of.
With this run of the agents, 47 generated tests need to be reviewed. The 936-line page analysis needs to be reviewed. The healer’s locator fixes need to be reviewed. The agent definitions need to be reviewed. The auto-generated CLAUDE.md needs to be reviewed. None of it can be skipped, especially in a payment platform where a test that passes when it should not is actively dangerous.
The time I saved generating tests, I am spending reviewing them. That is the price of delegating to AI.
I have worked using AI for over a year and I have yet to see real time-saving benefits. Before skills, it was arguing with AI on best code practices and correcting it. Now it is reviewing code and writing better markdown files for it. AI is like my 7 year old daughter. Highly intelligent but inexperienced and needs its hand held.